Machine Learning Articles of the Week: Big Data Neuroscience Pipeline, State of NLP, Compressed NNs, Faster NNs, and Improving Police Sketches with Genetic Algorithms
5 Takeaways on the State of Natural Language Processing
This is a collection of takeaways from a recent NLP get together: Word2Vec is popular and doing more than analogy parlor tricks, production grade NLP is popular, open source tools are not being sponsored, RNNs are popular, and there is a massive gender imbalance.
One of the interesting presentations being summarized here was how StitchFix is using word2vec on user’s comments to improve recommendations.
Compressing Neural Networks with the Hashing Trick
Motivated by computational and memory pressures with mobile architectures, the authors created a trainable hashed neural network that randomly groups weights into hashed buckets shared throughout the network. Their method can achive a compression factor of 1/64 with 2% error in MNIST.
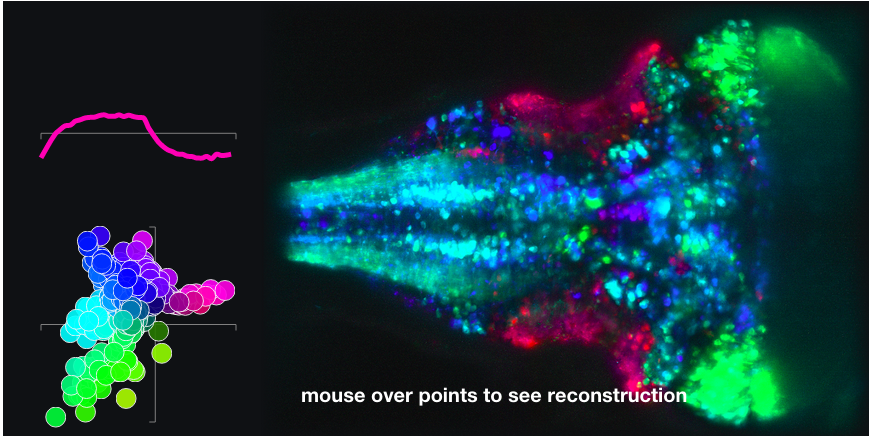
Analyzing + Visualizing Neuroscience data by Jeremy Freeman
Jeremy Freeman of HHMI’s Janelia Farm Research Campus gave a very cool presentation of his state of the art realtime and batch big data pipeline using python, Spark, d3, and a lot of custom bits to provide a clean and interactive analysis and visualization system called Thunder and Lightning respectively. The code is completly open source and available on github.
Caffe con Troll: Shallow Ideas to Speed Up Deep Learning
Thinking about computer architecture and using smart blocked matrix operations provide big speedups (4.5x end to end) on CPU and GPU for Caffe, a deep learning framework. The authors suggest current approaches with CPU vs GPU measurements have a poor implementation of Deep Learning on the CPU, causing CPU performance numbers to underperform.
The Psychology of Police Sketches - And Why They’re Usually Wrong
Randomized feature selection algorithmicly generate police sketches with genetic algorithms improves conviction rate and hopefully reduces bias.